Biography
I am a master’s student in Microelectronics at the School of Microelectronics, University of Science and Technology of China (USTC), advised by Assoc. Prof. Song Chen. I am currently a CSC-sponsored visiting graduate student at Nanyang Technological University (NTU), hosted by Assoc. Prof. Weichen Liu.
My research lies at the intersection of AI systems and electronic design automation (EDA). I work on efficient inference and compression for large language models, particularly Mixture-of-Experts (MoE) LLMs, and on structure-aware LLM pipelines for hardware code generation. I am drawn to problems that pair algorithmic insight with systems-level efficiency.
Recent News
May/2026: BitsMoE is available on arXiv, focusing on mixed-precision quantization for MoE LLMs.
Research Interests
- MoE LLMs efficient inference: mixed-precision quantization, expert-aware compression, memory-efficient serving
- Compression and adaptive quantization for MoE LLMs: spectral decomposition, activation-aware bit budgeting, ultra-low-bit deployment
- LLMs for EDA and hardware design automation: design understanding, automated RTL workflows, hardware-aware generation
- Structure-aware LLMs for RTL / Verilog generation: retrieval-augmented generation, graph-based hardware representations, multimodal soft prompting
- LLM agents for EDA: tool-integrated reasoning with synthesis and verification feedback
Selected Research Directions
MoE LLMs Efficient Inference
Efficient MoE deployment requires preserving expert-specialized capacity while reducing resident memory and inference overhead. My work studies quantization and allocation strategies that make sparse LLMs practical under strict deployment budgets.
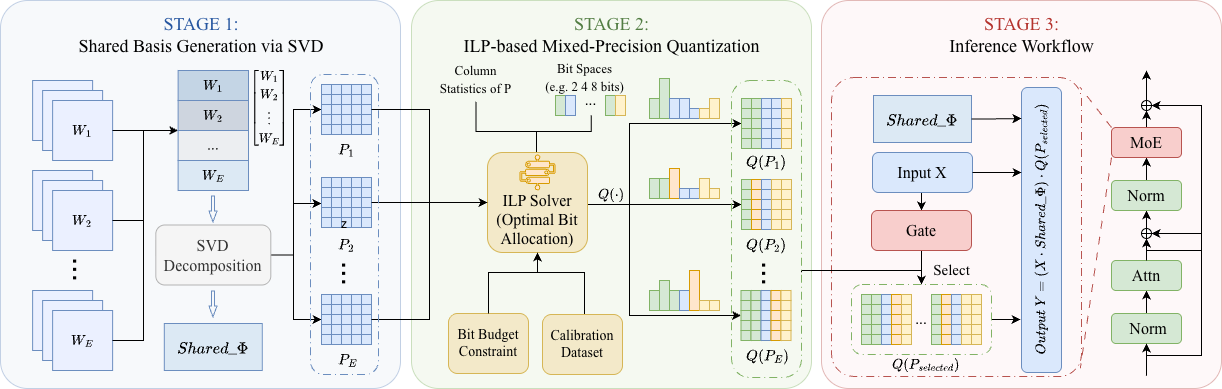
BitsMoE: Efficient Spectral Energy-Guided Bit Allocation for MoE LLM Quantization. arXiv preprint, 2026. (Paper) (Code)
Introduces spectral energy-guided bit allocation for MoE LLM quantization, using activation-aware mixed precision to preserve expert-specific capacity under low-bit memory budgets.
Keywords: MoE LLMs; mixed-precision quantization; spectral energy; efficient inference.
Education
University of Science and Technology of China (USTC), Anhui, China
M.Sc. student in Microelectronics, School of Microelectronics · Sep 2024 – Jun 2027 (expected)
Advisor: Assoc. Prof. Song Chen
My master’s training focuses on efficient large language model systems and model compression, with current work on mixed-precision quantization and efficient inference for MoE LLMs. I am also involved in LLM-based EDA research, especially structure-aware RTL and Verilog generation.
Nanyang Technological University (NTU), Singapore
Visiting Graduate Student, College of Computing and Data Science (CCDS) · Aug 2025 – Jul 2026
Host Supervisor: Assoc. Prof. Weichen Liu
I am visiting NTU under the China Scholarship Council (CSC) joint master’s training program, working on efficient inference and quantization methods for sparse LLMs.
University of Science and Technology of China (USTC), Anhui, China
B.Sc. in Physics, Minor in Computer Science · Sep 2020 – Jun 2024
During my undergraduate study, I built a foundation in physics, mathematics, and computer science, and gradually shifted my research focus toward AI systems, model compression, and hardware-aware machine learning.